In my Python CLI optimization post, Logria-py used a “smart poll rate” to reduce the speed at which the app checked for new messages from a stream. This technique used a timestamp and the count of messages to determine the millisecond average between message retrievals. The program then invoked time.sleep() for that amount to delay screen render routines.
In the Rust implementation, the architecture is slightly different. Instead of blocking with time.sleep() like the Python architecture, Logria uses crossterm’s poll() method in lieu of sleeping the CPU 1. Thus, there is no wake-up time for long delays on slow streams because input always immediately executes. The Rust architecture is built around a main app loop like so:
loop {
// Read messages from streams to internal buffer
let num_new_messages = self.recieve_streams();
// Update the poll rate to match stream speed
self.handle_smart_poll_rate(self.config.loop_time.elapsed(), num_new_messages);
if poll(Duration::from_millis(self.config.poll_rate))? {
self.render_logic_here();
}
}
The Rust poll rate algorithm started out looking like this:
/// Determine a reasonable poll rate based on the speed of messages received
fn handle_smart_poll_rate(&mut self, t_1: Duration, new_messages: u64) {
if self.config.smart_poll_rate {
// Set the poll rate to the number of milliseconds per message
self.update_poll_rate(
(t_1.as_millis() as u64)
.checked_div(new_messages)
.unwrap_or(SLOWEST)
.clamp(FASTEST, SLOWEST),
);
// Reset the timer we use to count new messages
self.config.loop_time = Instant::now();
}
}
There are two scenarios where new_messages can be zero:
1 message per second, it will sometimes find nothing new.1 message per millisecond and it slows for even a single loop, it will sometimes find nothing new.Both of these situations lead to checked_div() returning None, which means handle_smart_poll_rate sets the poll rate to SLOWEST 2. For the first scenario, this is the expected behavior: no new messages means Logria is looking at a slow stream and should not check for updates faster. For the second scenario, however, this is not the case. If this scenario occurs when reading from a fast stream, it will cause the app to pause execution while it waits for poll() for SLOWEST milliseconds. This is problematic because the continual toggling between these states can be jarring and make for a poor user experience3.
The logic for how Logria counts new messages looks like this:
/// Update stderr and stdout buffers from every stream's queue
fn recieve_streams(&mut self) -> u64 {
let mut total_messages = 0;
for stream in &self.config.streams {
// Read from streams until there is no more input
while let Ok(data) = stream.stderr.try_recv() {
total_messages += 1;
self.config.stderr_messages.push(data);
}
while let Ok(data) = stream.stdout.try_recv() {
total_messages += 1;
self.config.stdout_messages.push(data);
}
}
total_messages
}
If Logria instead counts total_messages from 1, then checked_div() can be removed. Adjusting the starting value makes the second scenario work, but creates a problem for the first: a slow stream or a static file will always return the same value they were initially set to when the app started. For example, if we read in a 100 line file in 1 millisecond, the first loop would see 100 messages in 1 millisecond, determine that the rate needed to be clamped to 1 millisecond per message, and continually use that value.
Receiving streams that are empty takes so little time it does not register on a millisecond scale. Thus, when Logria calls handle_smart_poll_rate(), t_1 is always 1 or 0, both of which when divided by 1 get clamped to FASTEST 4. This means slow streams never get the benefit of a lower poll rate, which defeats the purpose of having a smart poll rate.
A running mean is easy and computationally lightweight to keep track of. Leveraging Rust’s std::vec_deque, the implementation is as follows:
pub struct RollingMean {
pub deque: VecDeque<u64>, // u64 from `crossterm::event::poll`
sum: u64,
size: u64,
max_size: usize,
}
impl RollingMean {
pub fn new(max_size: usize) -> RollingMean {
RollingMean {
deque: VecDeque::with_capacity(max_size),
sum: 0,
size: 0,
max_size,
}
}
pub fn update(&mut self, item: u64) {
if self.deque.len() >= self.max_size {
self.sum -= self.deque.pop_back().unwrap();
} else {
self.size += 1;
}
self.deque.push_front(item);
self.sum += item;
}
pub fn mean(&self) -> u64 {
self.sum / self.size
}
pub fn reset(&mut self) {
self.sum = 0;
self.size = 0;
self.deque.clear();
}
}
However, as a statistic, a mean emphasizes outliers, which means that it does not solve the problem. Given a VecDeque that contains [25, 25, 25, 25, 1000], the mean is 220, which is too long a wait for a stream running at approximately 25 milliseconds per message.
A basic Backoff struct can look like this:
pub struct Backoff {
num_cycles: u64,
previous_base: u64,
}
The math to keep track of the backed-off value is also quite simple:
pub fn determine_poll_rate(&mut self, poll_rate: u64) -> u64 {
// Poll rate is capped to SLOWEST in the reader
if poll_rate > self.previous_base || poll_rate == SLOWEST {
let increase = self.previous_base * self.num_cycles;
self.num_cycles = self.num_cycles.checked_add(1).unwrap_or(1);
self.previous_base = min(min(self.previous_base + increase, poll_rate), SLOWEST);
self.previous_base
} else {
self.num_cycles = 1;
self.previous_base = max(poll_rate, 1);
poll_rate
}
}
The min(min(...)) line could be rewritten as:
self.previous_base = *[self.previous_base + increase, poll_rate, SLOWEST]
.iter()
.min()
.unwrap_or(&poll_rate);
However, unless the slice had more than a few items, the code is less readable.
Regardless of the style, the Backoff strategy forces the poll rate to expand as a factor of multiple growth periods, not all at once. On its own, however, this can cause problems. If a stream has high message timing variance, the poll rate remains unstable:
| Loop | Timing | Poll Delay |
|---|---|---|
| 1 | 50 | 50 |
| 2 | 50 | 50 |
| 3 | 900 | 100 |
| 4 | 900 | 200 |
| 5 | 50 | 50 |
While the backoff factor might be adjusted to make growth occur more gradually, Logria already uses the lowest possible integer, 2, to grow the poll rate.
To ensure the poll rate as stable as possible, Logria can leverage a combination of both the RollingMean and Backoff strategies.
Using the Backoff algorithm inside of our RollingMean struct, all Logria needs to do is modify the update() method to calculate the adjusted_item:
pub fn update(&mut self, item: u64) {
if self.deque.len() >= self.max_size {
self.sum -= self.deque.pop_back().unwrap();
} else {
self.size += 1;
}
let adjusted_item = self.tracker.determine_poll_rate(item);
self.deque.push_front(adjusted_item);
self.sum += adjusted_item;
}
Given message timings of [25, 25, 25, 25, 1000], the VecDeque would now contain [25, 25, 25, 25, 50]. If there are no messages or the stream is idle, it takes 7 loops to grow the poll rate to the ceiling of 1000 ms 5.
| Loop | Mean | VecDeque |
|---|---|---|
| 0 | 50 | [] 6 |
| 1 | 100 | [100] |
| 2 | 200 | [300, 100] |
| 3 | 466 | [1000, 300, 100] |
| 4 | 600 | [1000, 1000, 300, 100] |
| 5 | 680 | [1000, 1000, 1000, 300, 100] |
| 6 | 860 | [1000, 1000, 1000, 1000, 300] |
| 7 | 1000 | [1000, 1000, 1000, 1000, 1000] |
After implementing both the Backoff struct and the RollingMean struct, Logria updates the poll rate using the following logic:
/// Determine a reasonable poll rate based on the speed of messages received
fn handle_smart_poll_rate(&mut self, t_1: Duration, new_messages: u64) {
if self.config.smart_poll_rate && !(InputType::Startup == self.input_type) {
// Set the poll rate to the number of milliseconds per message
let ms_per_message = (t_1.as_millis() as u64)
.checked_div(new_messages)
.unwrap_or(SLOWEST)
.clamp(FASTEST, SLOWEST);
self.config.message_speed_tracker.update(ms_per_message);
self.update_poll_rate(self.config.message_speed_tracker.mean());
// Reset the timer we use to count new messages
self.config.loop_time = Instant::now();
}
}
In this code, message_speed_tracker is a RollingMean struct that invokes Backoff when inserting values to its VecDeque.
Simulating using this algorithm is straightforward:
fn test_poll_rate_change_when_enabled_idle_multiple() {
let mut logria = MainWindow::_new_dummy();
logria.input_type = InputType::Normal;
assert_eq!(logria.config.poll_rate, 50); // Default on launch
logria.handle_smart_poll_rate(Duration::new(0, 10000000), 1);
assert_eq!(logria.config.poll_rate, 10);
logria.handle_smart_poll_rate(Duration::new(0, 10000000), 1);
assert_eq!(logria.config.poll_rate, 10);
logria.handle_smart_poll_rate(Duration::new(0, 10000000), 0);
assert_eq!(logria.config.poll_rate, 13);
// VecDeque: [10, 10, 20]
}
While previously this would have set the poll rate to SLOWEST, Logria now sets a stable poll rate that does not interrupt the feed of messages or user input.
I used htop filtered to processes called Logria in a split tumx window so I could run the app and see the CPU use at the same time.
On the home screen, the CPU is idle, as Logria does not check for stream input when there are no streams:
Because of the aforementioned changes, the same is true for files or streams that are not actively receiving data:
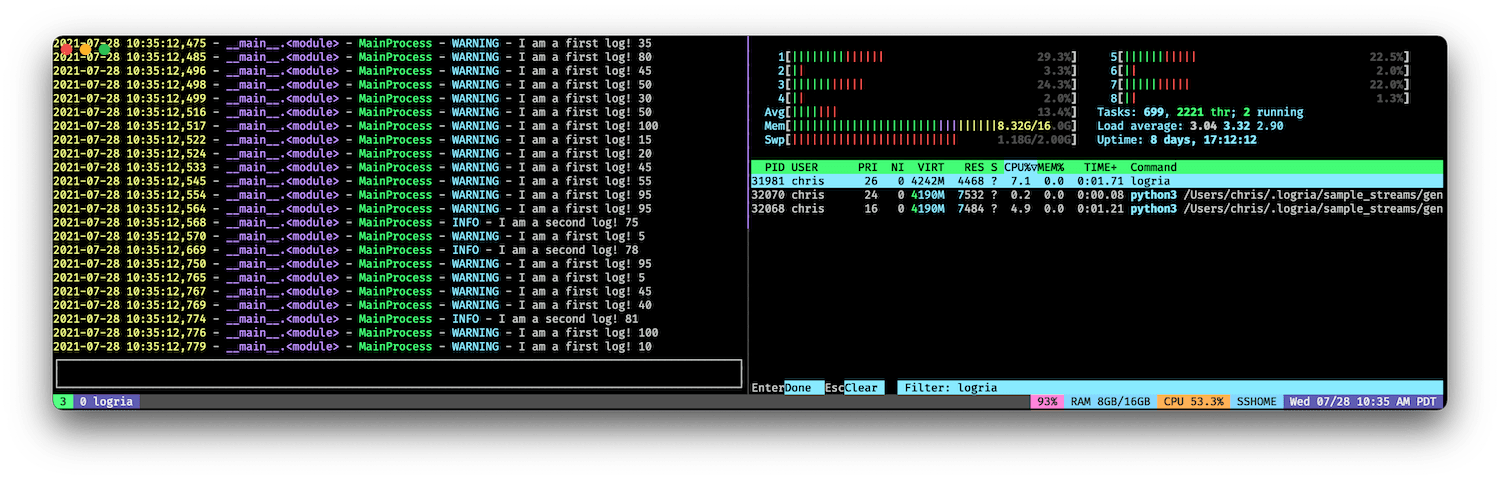
However, for a fast stream, Logria scales the poll rate (and uses more CPU) as it processes the data:
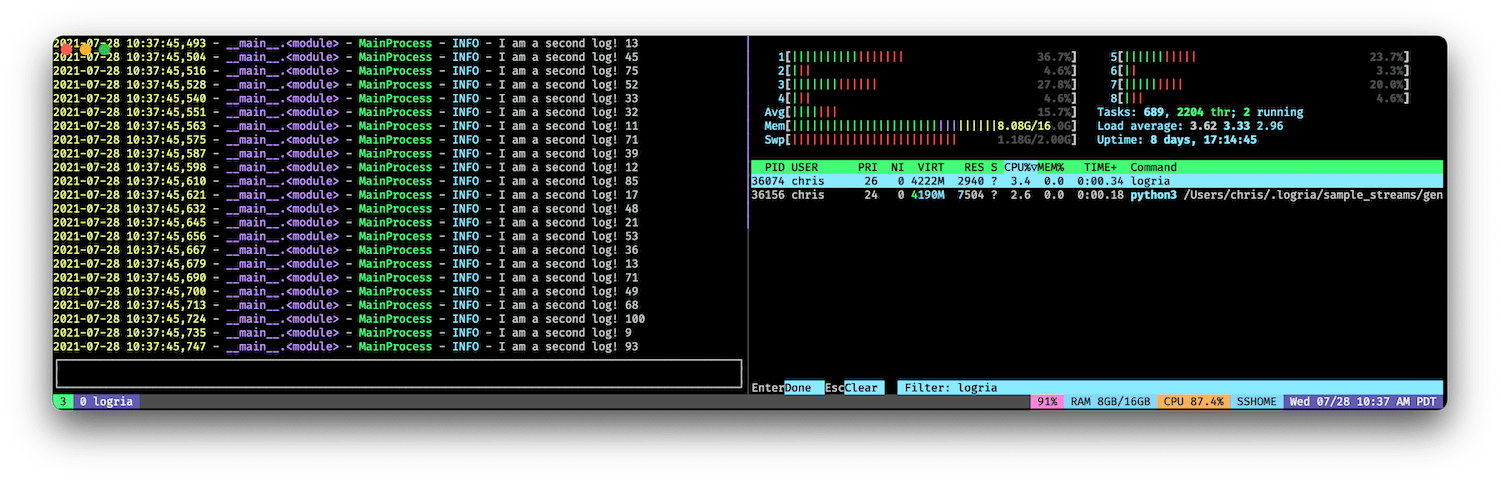
If the stream slows down, the CPU use decreases.
Adding cognitive complexity to software has costs and benefits. In this case, the added complexity of determining a smart poll rate has drastic effects on performance: Logria now scales the poll rate to use the smallest amount of CPU resources it requires to process text.